
OpenAI has released its new flagship model, GPT-4o. This new model can now reason with audio, vision and text in real time better than the earlier audio-only AI model.
GPT-4o (“o” for “omni”) is a step towards much more natural human-computer interaction because now the model will accept combinations of audio, text and image to generate any combination of text, audio and image.
The new model can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in a conversation. It will match the Turbo performance of GPT-4 on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models.
Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time: https://t.co/MYHZB79UqN
Text and image input rolling out today in API and ChatGPT with voice and video in the coming weeks. pic.twitter.com/uuthKZyzYx
— OpenAI (@OpenAI) May 13, 2024
Model Capabilities
The new model has enhanced capabilities in which you can not only give questions to get demanded responses but can also interact with the model. The model can now hold a conversation, a human skill, to solve the problem. The model’s voice just like humans can change depending on the conversation. The tone changes on demand with slow and fast-talking and singing on demand.
Prior to GPT-4o, you could use Voice Mode to talk to ChatGPT with latencies of 2.8 seconds (GPT-3.5) and 5.4 seconds (GPT-4) on average. The present model takes audio as input and then translates it into text, or text into text and the model turns text into audio. This leads to loss of information and loss of ‘human essence’. The model couldn’t detect tone of the speaker, background noises, or emotions of laughter or sadness.
This new model of GPT-4o is a single model end-to-end across text, vision and audio, meaning all inputs and outputs are processed by the same network, unlike the previous model.
As this is the first model to do all combine all types of inputs and outputs on the same network, there are some areas which still needs to be explored to cross the limitations.
Model Evaluations
The new GPT-4o sets new high watermarks on multilingual, audio and vision capabilities.
GPT-4o sets a new high score of 87.2 per cent on 5-shot MMLU (general knowledge questions).
The Audio ASR performance of GPT-4o is better in all regions as compared to Whisper-v3. In all regions, the mistakes/errors are lower in the new model. It dramatically improves speech recognition performance over Whisper-v3 across all languages, particularly for lower-resourced languages.
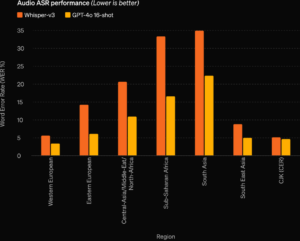
The model also outperforms the Whisper-v3 in speech translation on the MLS benchmark.
The M3Exam Benchmark is both a multilingual and vision evaluation, consisting of multiple choice questions from other countries’ standardized tests that sometimes include figures and diagrams. GPT-4o is stronger than GPT-4 on this benchmark across all languages.
In evaluation tests for visual perception benchmarks, GPT-4o performs better than all the other present models like Gemini 1.0 Ultra, GPT-4T and Claude Opus.

Model Safety and Limitations
GPT-4o has safety built-in by design across modalities, through techniques such as filtering training data and refining the model’s behaviour through post-training.
The evaluations of cybersecurity, CBRN, persuasion and model autonomy show that GPT-4o doesn’t score above medium risk in any category. GPT-4o has also undergone extensive external red teaming with 70+ external experts in domains such as social psychology, bias and fairness, and misinformation to identify risks that are introduced or amplified by the newly added modalities.
Over the upcoming weeks, OpenAI will be working on technical infrastructure, usability via post-training, and safety necessary to release the other modalities.
GPT-4o Model availability
GPT-4o’s text and image capabilities are starting to roll out today in ChatGPT. GPT-4o is made available in the free tier, and to Plus users with up to 5x higher message limits. A new version of Voice Mode with GPT-4o in alpha within ChatGPT Plus will also roll out in the coming weeks.










{kind=link}
Comments 2